
소개 영상:
모든 데이터에 빠르고 안정적이며 안전하게 액세스하십시오
여러 클라우드에서 사용 가능한 Snowflake 플랫폼은 다양한 데이터 유형과 스토리지 패턴을 지원하여 사일로를 없앱니다. 조직 전반의 데이터 엔지니어, 데이터 과학자, 분석가 및 개발자는 리소스의 경합이나 동시성의 문제에서 벗어나 다양한 워크로드에 정형, 반정형, 비정형 등의 관리형 데이터에 액세스할 수 있습니다.
SNOWFLAKE 데이터 레이크를
사용해야 하는 이유
모든 데이터, 단일 플랫폼
귀하의 니즈에 가장 잘 맞는 스토리지 패턴을 사용해 정형, 반정형 및 비정형 데이터를 원활하게 사용하십시오.
신속하고 안정적인 진행과 쿼리 처리
탄력적인 엔진으로 아키텍처를 간소화하여 많은 워크로드를 처리함으로써 사실상 동시성 문제나 리소스 경합이 거의 없습니다.
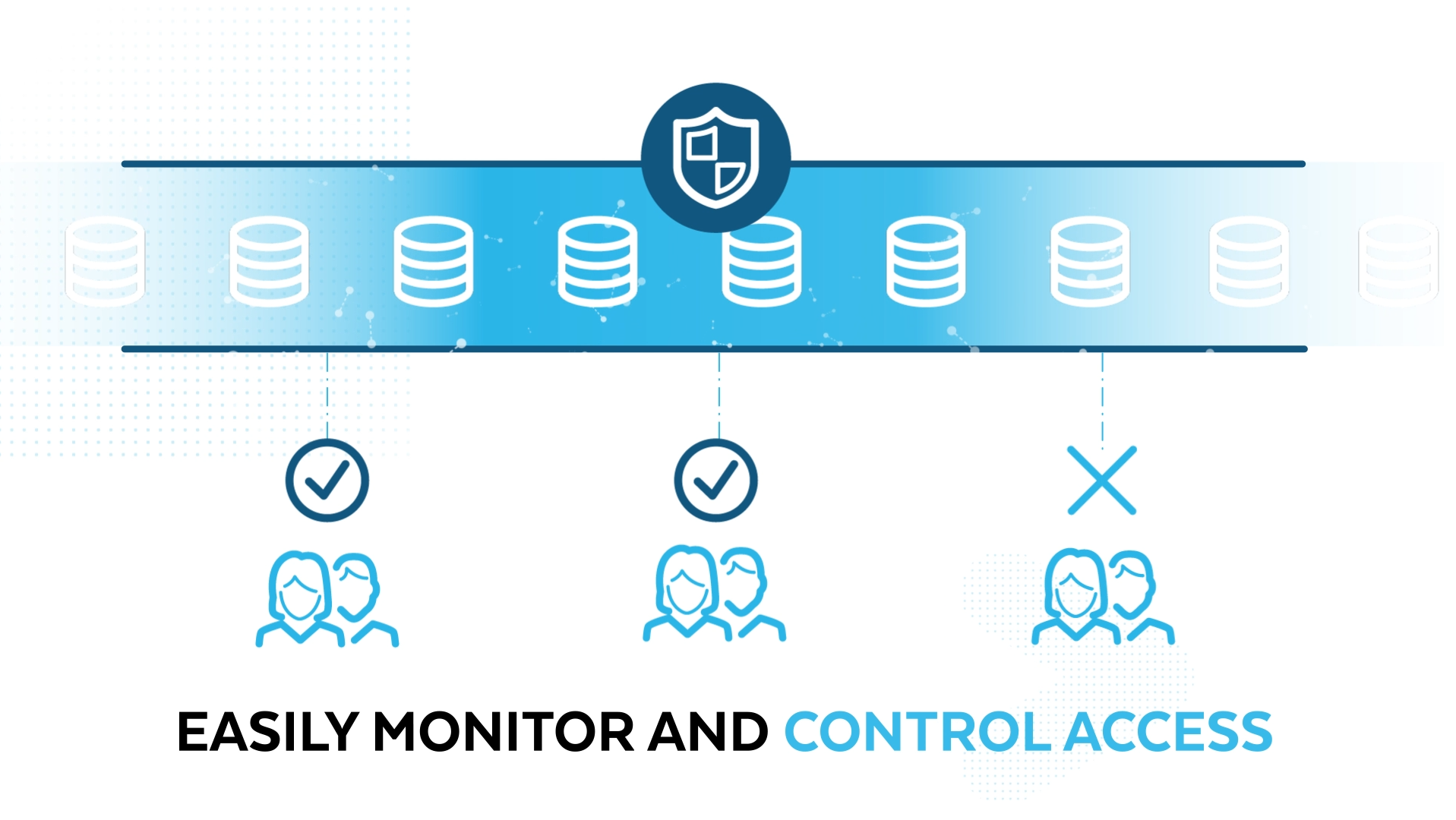
안전한 협업 활성화
데이터 레이크를 보호하고 그 안에 무엇이 있는지 파악하며 사용 방식을 제어할 수 있습니다. ETL 없이 외부 데이터를 쉽게 통합합니다.
SNOWFLAKE가 데이터 레이크를
지원하는 방법
서로 다른 데이터를 한 곳에서 통합
- 단일 플랫폼에서 선택한 언어로 정형, 반정형 및 비정형 데이터에 대한 많은 워크로드를 지원하므로 서비스와 시스템을 연결할 필요가 없습니다.
- 효율적인 압축, 자동 마이크로 파티셔닝, 저장 및 전송 중 암호화 기능을 통해 Snowflake가 관리하는 스토리지에 데이터를 저장합니다.
- 데이터를 이동할 필요 없이 기존 클라우드의 오브젝트 스토리지 데이터에 액세스합니다.

신속하고 안정적인 데이터 처리 및 쿼리
- 안정적인 성능과 비용 절감이 가능하며, 유지 관리가 거의 필요 없는 Snowflake의 탄력적인 처리 엔진으로 파이프라인을 실행합니다.
- 스키마 온 리드(Schema-on-Read)의 유연성을 유지하면서도 관계형 쿼리의 속도로 반정형 데이터를 빠르게 처리합니다.
- 거의 무제한에 가까운 전용 컴퓨팅 리소스를 사용하여 제한 없는 동시 사용자 및 쿼리를 지원합니다.
- Snowpark에서 추가 클러스터, 서비스 또는 데이터 사본을 관리할 필요 없이 SQL 또는 선택한 언어를 사용하여 파이프라인 개발을 간소화합니다.
모든 데이터를 쉽게 관리하고 안전한 협업 지원
- 역할 기반 액세스 정책을 통해 클라우드 전체에 행과 열 수준의 보안을 적용하므로 동일한 데이터의 여러 버전을 관리할 필요가 없습니다.
- 내장된 액세스 기록을 통해 누가 어떤 데이터에 액세스하는지 알 수 있습니다.
- 분류 및 객체 태깅을 통해 민감한 데이터를 식별하고 추적하며, 동적 데이터 마스킹 및 외부 토큰화를 통해 분석 값을 유지하면서 데이터를 보호합니다.
- 실시간 보안 데이터 공유를 통해 내부 및 외부 이해관계자 간의 협업을 지원하고 데이터 레이크의 수준을 높일 수 있습니다.
SNOWPARK로
비정형 데이터 처리
Snowflake에서 비정형 데이터를 저장하고 관리할 수 있을 뿐만 아니라 현재 공개 미리 보기가 제공되는 Snowpark에서 Java를 사용하여 해당 데이터를 처리할 수 있습니다. Quickstart를 통해 비정형 데이터를 Snowflake로 저장, 관리, 처리 및 공유하는 방법을 단계별로 시작해보십시오.
고객의
목소리
정형 및 반정형 데이터를 기본적으로 지원하는 Snowflake를 우리의 데이터 레이크로 이용함으로써 머신 러닝 모델에 대한 모든 관련 데이터에 쉽게 액세스할 수 있습니다.
Divy Murli
우리는 기업 내 모든 이에게 우리의 데이터 (레이크)를 공개했습니다. 사원증이 있고 회사 내에 출입이 가능한 직원이라면, 개인 식별 정보와 같이 접근을 제한할 특별한 이유가 없는 한 데이터를 볼 수 있습니다.
Larry Querbach
데이터 레이크는 숨겨진 보석이었습니다. 비용을 관리할 수 있으며 최적화하는 것에 대해서는 전혀 걱정할 필요가 없습니다.
William Homan-Muise
SNOWFLAKE로
구축하기
Snowflake 개발자 센터에서 앱, 데이터 파이프라인 및 ML 워크플로우를 구축하는 데 필요한 리소스를 찾으십시오.




다른 워크로드
살펴보기

데이터 사일로를 제거하고 조직 전체 또는 그 이상의 조직 간에서 관리되는 데이터를 즉각적이고 안전하게 공유합니다.