WORKLOADS
Snowflake für Data Engineering
Erstellen Sie leistungsstarke Streaming- und Stapeldaten-Pipelines in SQL oder Python.




Vereinfachung komplexer Data-Engineering-Anforderungen
Erstellen Sie Streaming- und Stapeldaten-Pipelines auf einer einzigen Plattform mit der Leistung von deklarativen Pipelines und kosteneffizienter inkrementeller Aktualisierung.
Beseitigung unnötiger Pipelines dank Data Sharing
Greifen Sie über den Snowflake Marketplace direkt auf einsatzbereite Live-Daten aus Tausenden von Datasets und Apps zu, ohne Pipelines erstellen zu müssen.
Programmierung in bevorzugter Sprache – mit nur einer optimierten Engine
Programmieren Sie z. B. in Python oder SQL und nutzen Sie anschließend zur Ausführung die Multi-Cluster-Rechenressourcen von Snowflake. Keine separate Infrastruktur erforderlich.
So funktioniert es
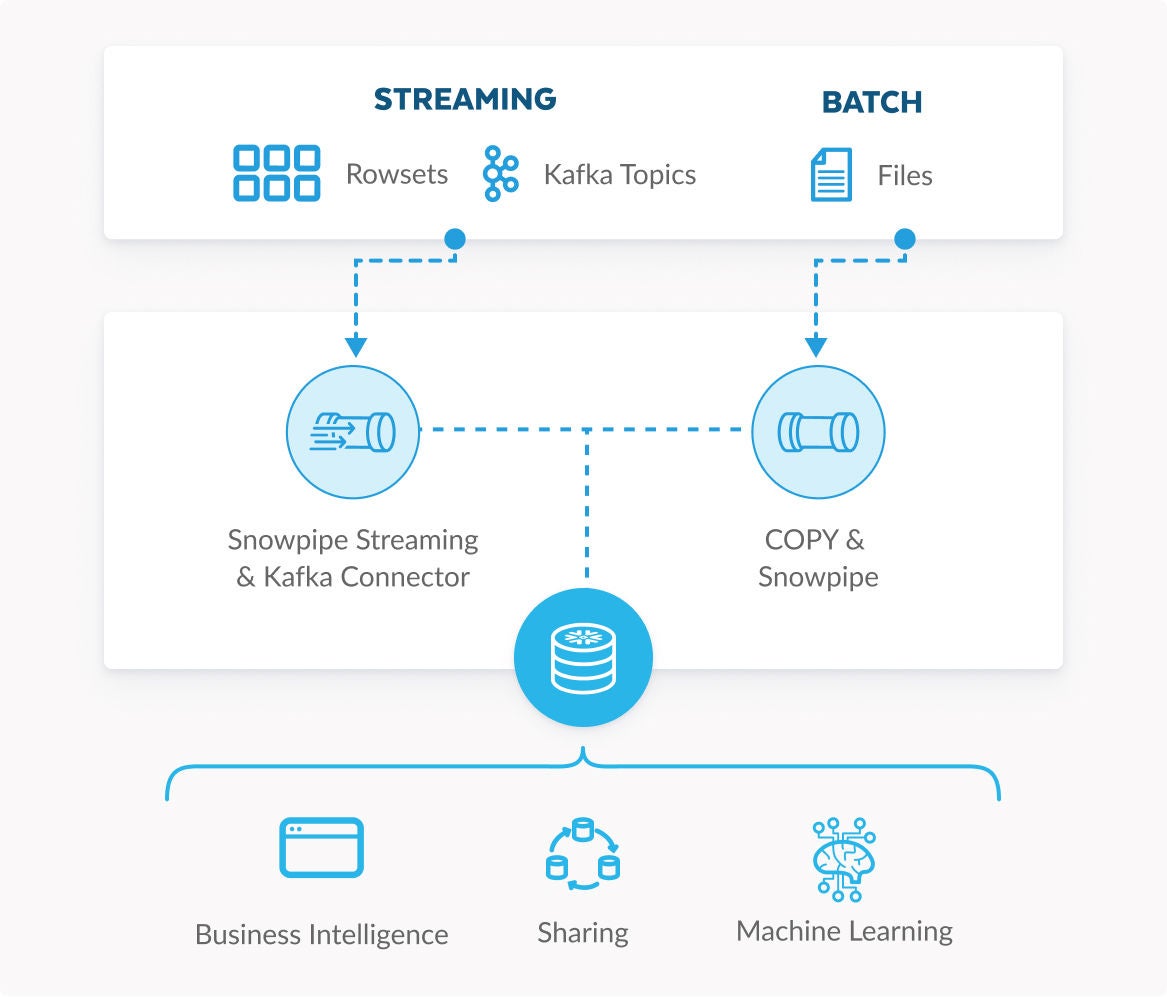
Streamen Sie Daten mit einer Latenzzeit von weniger als 10 Sekunden
Streaming- und Stapeldaten-Systeme werden oft getrennt gehalten und sind in der Regel komplex zu verwalten und kostspielig zu skalieren. Doch mit Snowflake können Sie in einem einzigen System sowohl Streaming- als auch Stapeldaten unkompliziert erfassen und umwandeln.
Streamen Sie mit Snowpipe Streaming zeilenweise Daten nahezu in Echtzeit mit einer Latenz im einstelligen Bereich oder erfassen Sie Dateien automatisch mit Snowpipe. Zur Steigerung der Skalierbarkeit und Kosteneffizienz erfolgt beides serverlos.
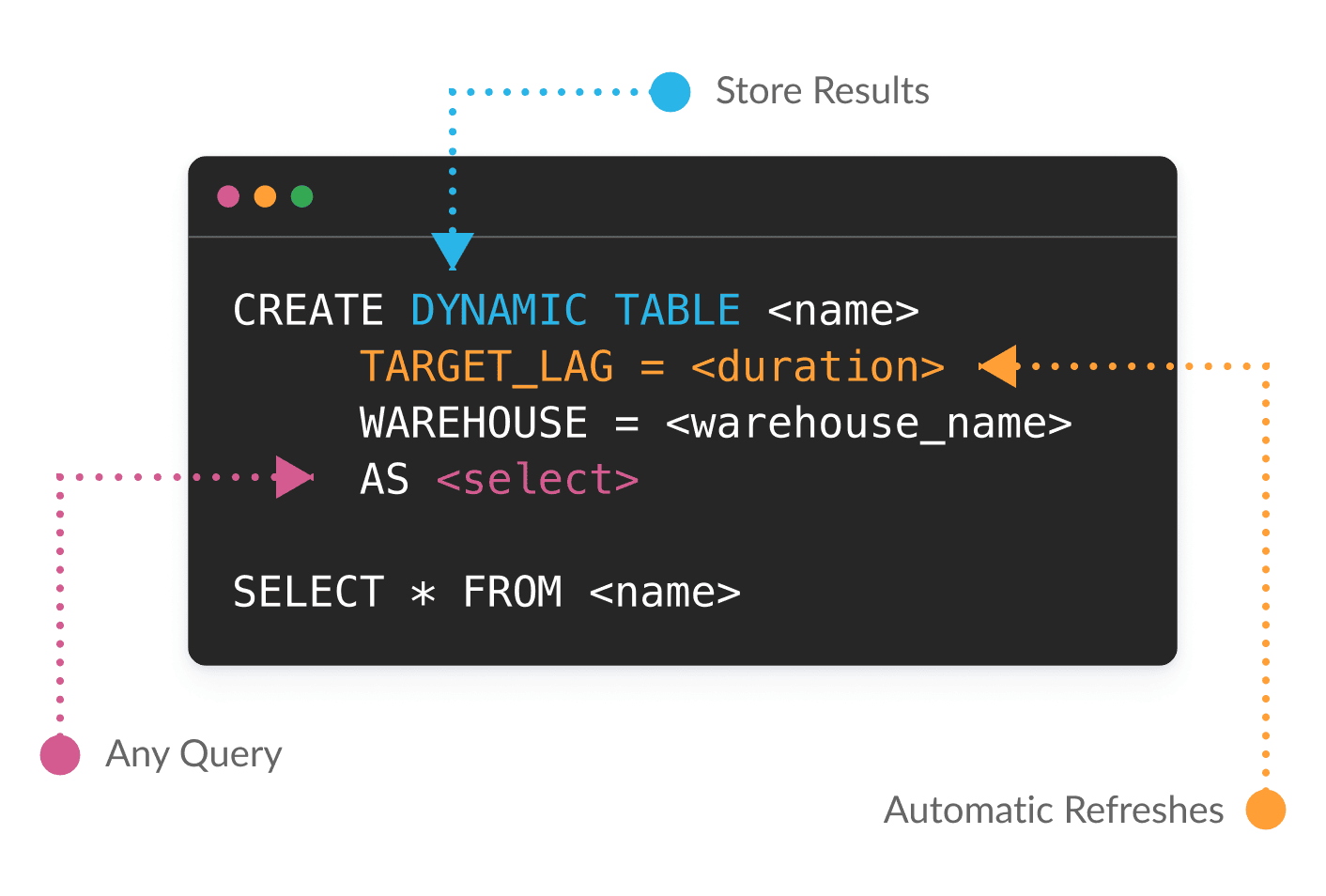
Passen Sie die Latenz mit einer einzigen Parameteränderung an
Mit Dynamic Tables (in Public Preview) können Sie SQL oder Python verwenden, um Datenumwandlungen deklarativ zu definieren. Snowflake verwaltet die Abhängigkeiten und stellt automatisch Ergebnisse auf der Grundlage Ihrer Ziele hinsichtlich Aktualität bereit. In Dynamic Tables werden nur die Daten verarbeitet, die sich seit der letzten Aktualisierung geändert haben, um große Datenmengen und komplexe Pipelines einfacher und kosteneffizienter zu gestalten.
Je nach Geschäftsanforderungen können Sie eine Stapeldaten-Pipeline problemlos in eine Streaming-Pipeline umwandeln, indem Sie eine einzige Änderung an den Latenzparametern vornehmen.
Unterstützen Sie Data Engineering für Analytik, KI/ML und Applikationen
Bringen Sie Ihre Workloads zu den Daten, um die Pipeline-Architektur zu optimieren und die Notwendigkeit einer separaten Infrastruktur zu eliminieren.
Bringen Sie Ihren Code zu den Daten, um eine Vielzahl von Geschäftsanforderungen zu erfüllen – von der Beschleunigung der Analytics über die Entwicklung von Apps bis hin zur Optimierung der Nutzung von generativer KI und LLMs. Dank Snowpark kann dieser Code in der von Ihnen bevorzugten Sprache erstellt werden, sei es SQL, Python, Java oder Scala.
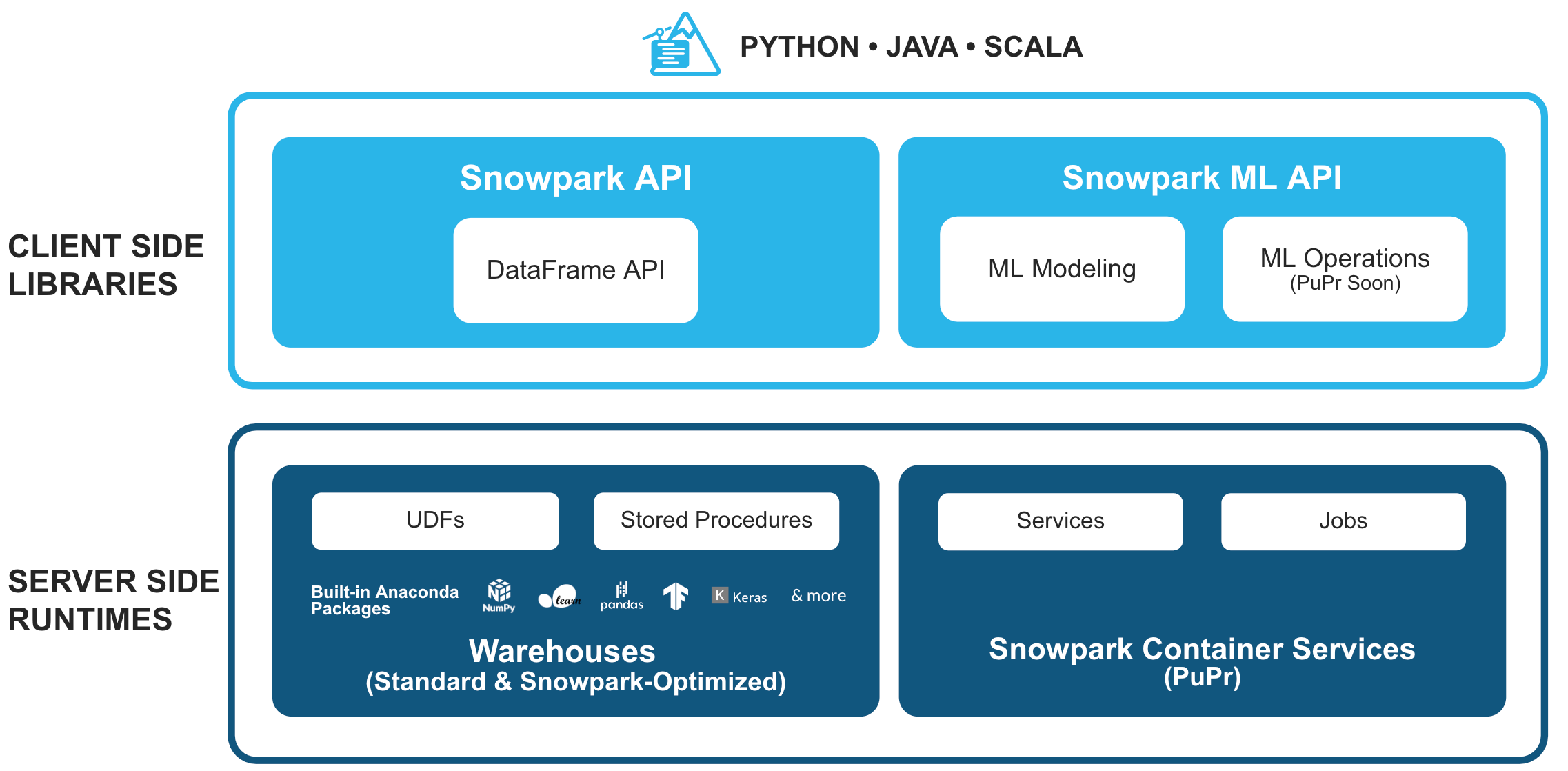
Erzielen Sie eine 3,5-fach schnellere Performance und 34 % Kosteneinsparung – ohne Kompromisse bei der Governance
Programmieren Sie mit Python, Java oder Scala und nutzen Sie die Snowpark-Bibliotheken, wie z. B. die DataFrame API, sowie Laufzeitumgebungen, darunter UDFs und Stored Procedures. Anschließend können Sie Ihren Code auf sichere Weise dort bereitstellen und verarbeiten, wo sich Ihre Daten befinden – und das alles mit konsistenter Governance in Snowflake.
Mit Snowpark erzielen die Kunden im Vergleich zu verwalteten Spark-Lösungen im Durchschnitt eine 3,5-fach schnellere Performance und 34 % niedrigere Kosten.1
Entwickeln Sie weniger Daten-Pipelines dank einfachem Data Sharing
Mit der Data Cloud steht Ihnen ein riesiges Netzwerk von Daten und Applikationen zur Verfügung.
Greifen Sie einfach auf Daten und Applikationen zu und stellen Sie sie mit direktem Zugriff auf Live-Datasets aus dem Snowflake Marketplace zur Verfügung. So reduzieren Sie die Kosten und den Aufwand, die mit herkömmlichen ETL-Pipelines (Extrahieren, Transformieren und Laden) und API-basierten Integrationen einhergehen. Oder verwenden Sie einfach native Konnektoren, um Daten einzuspeisen.
UNSERE KUNDEN
Führende Unternehmen nutzen Snowflakefür Data Engineering





ErsteSchritte
Hier finden Sie alle Data-Engineering-Ressourcen, die Sie für die Erstellung von Pipelines mit Snowflake benötigen.

Quickstarts
Mit den Snowflake-Tutorials für Data Engineering können Sie sofort loslegen.

Virtual Hands-On Lab
Nehmen Sie an einem geleiteten Virtual Hands-On Lab teil, um zu erfahren, wie Sie Daten-Pipelines mit Snowflake einrichten können.

Snowflake-Community
Treffen Sie führende Datenexpert:innen im weltweiten Netzwerk der Snowflake-Community im Forum und in den Snowflake-Nutzergruppen und erwerben Sie neues Wissen.
1Datenquelle: Kundenerfolge mit Snowpark